Managing data on cloud platforms can be an extremely difficult task. The need to store data efficiently, both in terms of energy and monetary cost, dictates the existence of tiered storage for data written and read at different frequencies. Avoiding a complicated user interface is therefore a great challenge, as in most cases the user is tasked with interacting with the different storage media directly, having to learn APIs and complex tape semantics to be able to effectively manage their data.
We at CEDA do not like proliferating barriers to effective data management, and hence are developing a new storage interface precisely to counteract these problems. The Near-line Data Store (NLDS), a single interface for moving data between storage solutions on JASMIN, is intended to replace the Joint Data Migration App (JDMA) and streamline the process by which users migrate data between storage media on our system. By providing a single, easy to use interface for adding, changing and removing data, we aim to abstract away the complexities involved and instead provide a seamless storage experience. Here, we discuss the principles on which this new application was designed, the current state of development, and detail a brief timeline going forward.
Index
- Index
- Background
- Requirements
- Design
- Current progress
- Next steps
- Summary
- Acknowledgements
- Software Stack
Background
The JDMA currently operates as the data migration tool on JASMIN, allowing users to submit files, and lists of files, to be copied/transferred to either the object store, or tape storage system on JASMIN. This was developed a few years ago at CEDA and, while fully functioning and secure, has several drawbacks in the way it was designed - notably the lengthy time required to transfer even small batches of files due to the way check-summing is handled. It is also limited in that it requires the user to actively choose where data is stored and moved to, limiting the usefulness of tape as a cost- and energy-saving medium due to limited user uptake.
Requirements
A new application is therefore proposed to overcome these drawbacks by providing a single interface for users to interact with. By splitting the storage into tiers of “Hot”, “Warm” and “Cold” – referring to disk, object storage, and tape respectively – and having a policy for moving data between these media based on frequency of access, more efficient use of storage resources is achieved without reliance on user behaviour. In fact, users no longer need worry about where on JASMIN their data is stored at all, merely that it is accessible when they require it. This can be considered the first design requirement for the new application.
A further design requirement was the use of a RESTful API, a modern web application interface which would allow the system to be hosted as a single online web endpoint accessible through HTTP requests. This is a very general approach, with the upshot being that we can provide a client library which implements this API and therefore allows easy access to the system, while also not stifling the creation of alternative clients and tools written by others. It also facilitates a ‘send-and-forget’ workflow, whereby the user only needs to input the initial command to start the procedure and no continuous connection is required past that point.
Another important design requirement was portability. The funding secured for this project through the ESiWACE2 project (Centre of Excellence in Simulation of Weather and Climate in Europe) stipulated that the app should be fully portable, i.e. deployable generally in any location or supercomputing facility which requires a tiered storage interface. Put simply, it should not be JASMIN-specific.
A final design requirement was the need to follow the CRUD mnemonic, standing for create, read, update, destroy.
This is the standard for interfacing with any storage medium, and within a RESTful API would correspond to the HTTP commands put, get, and del, where put covers both the create and update methods required by CRUD.
Design
The design settled upon was a microservice architecture, utilising several tools already used successfully in other CEDA development projects. The general structure is as follows:
- An API server, that clients connect to and issue commands to. The commands are, as above, the CRUD commands:
put,putlist,get,getlist,del,dellist. - A message-broker queue. The API server translates the user’s commands to messages and pushes them onto the message-broker queue.
- Micro-service subscribers to the queue. These micro-services take a message from the queue, perform a task that is encoded in the message, and then push the results back onto the queue for further action.
- A transfer processor.
- A monitoring and notification system.
- A catalogue database, containing the NLDS holdings.
This basic architecture is illustrated in Figure 1.
Note that the additional *list commands on the API server – while not standard HTTP commands – allow particular text files, comprised of lists of files and directories, to be handled in one command.
This was a standard workflow in JDMA.
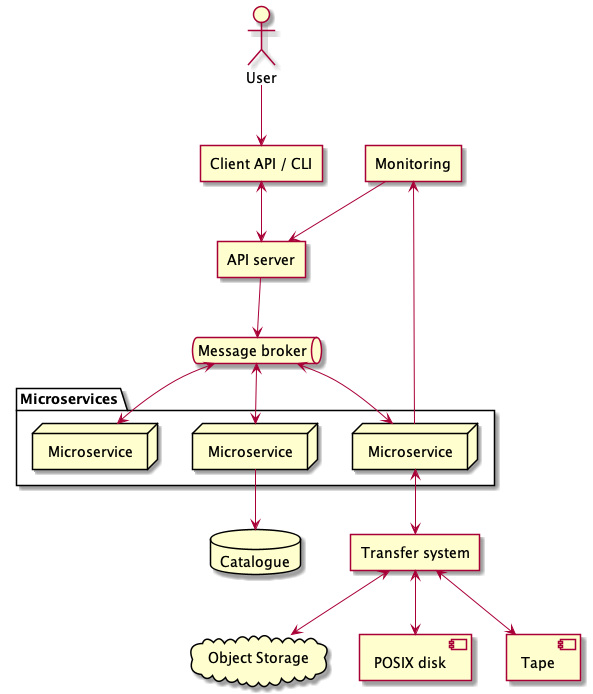
Microservice architecture
Using microservices to organise your code has numerous advantages. By boiling down the program into self-contained modules, writing and maintaining the code base becomes easier. Each will have a clearly defined set of inputs and outputs, and doesn’t care what the rest of the program is doing at the same time, simply that it is doing its particular job effectively. This should be caveated with the fact that this only works if the scope of each microservice is properly and appropriately defined. Additionally, partitioning your program makes your application easily scalable and parallelisable: another, identical microservice can be spun up to help handle high load and each operates entirely independently. High workloads can therefore be treated as embarrassingly parallel problems, and no complex multi-threading or multi-processing is required.
In the case of the NLDS, the following microservices were defined:
- Worker: processes incoming messages from the API server
- Indexer: processes the file or file-list provided by the user and ensures that any directories are fully indexed for files. It also checks for permissions, corruption etc.
- Transfer: actually performs the file transfer requested by the user
- Cataloguer: adds records to the catalog database - containing the NLDS holdings
- Monitor: accessible by user to check the status of transfers
- Logger: accessible by sysadmin to check logs from each of the microservices
Message broker
This architecture requires a message broker to ensure that each of the microservices properly and asynchronously communicate with each other. For our purposes we chose RabbitMQ, an open-source, commercial quality messaging broker as it is widely used, is extremely flexible, and has a python client. It facilitates the architecture we aim to implement by allowing the user to set up an exchange and a number of queues: the exchange routes messages to each of the queues depending on a ‘routing key’, with several different exchange types available to modify how and when the exchange will do so.
The details of how we implemented this can be found in the queue system section.
Authentication
Authenticating the user and ensuring they only interact with files they have permissions for was a difficult task for the JDMA, and as such, easing its implementation in the NLDS was a core design goal. OAuth2 was selected as the method by which this could be done, given it is the modern standard and fits nicely within a RESTful architecture.
Current progress
In short, the current state of the NLDS is as follows:
- Client
- Client API: implemented with requests
- Client cli program: implemented with click
- PUT, PUTLIST, GET, GETLIST requests can be sent
- Server
- Implemented with fastapi and uvicorn
- Similarly PUT, PUTLIST, GET and GETLIST requests can be received
- Microservice layer
- Implemented with RabbitMQ messaging broker system
- Worker, Indexer and Logger are implemented and functional
Queue system
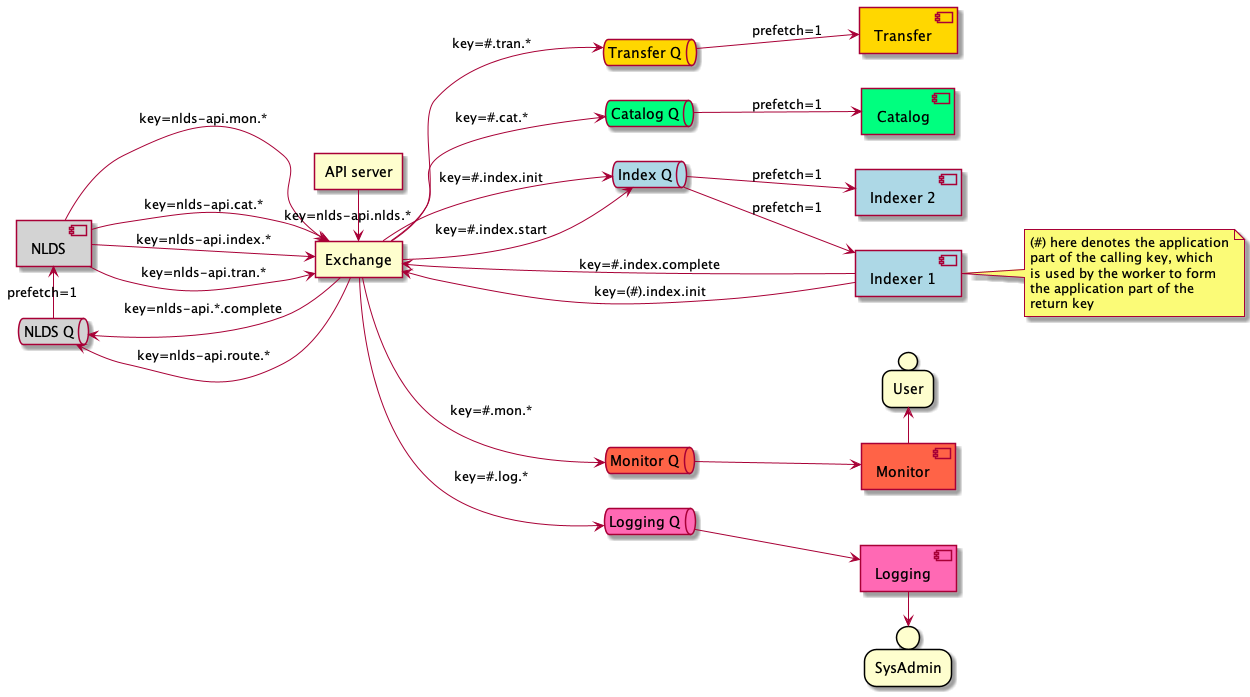
When implementing the rabbit queuing system, we opted for a ‘topic’ exchange type, whereby each routing key is comprised of several dot-separated parts and each queue only receives messages containing parts it is interested in hearing. Each queue will then accumulate messages until a consumer - a rabbit construct for taking messages from queues - reads and performs some action on the message before returning it to the exchange for further processing. The consumers are therefore where our microservices reside, acting on a set input of an expected message and returning a set output of a processed message to the exchange. They can also be scaled by simply increasing the number of concurrent consumers when a queue’s message backlog is sufficiently high.
We decided to use a 3-part routing key, with the parts denoting:
- The originating app – while this is only NLDS for now, other applications could easily be plugged into the same framework. This is also referred to as the ‘root’.
- The target microservice – e.g.
index,catalogetc. - The action to be performed – currently can be one of
start,init, orcomplete.
To give an example, a message with a routing key nlds-api.index.start is sent from the nlds, going to the indexer to begin the indexing process.
The proposed queue system is outlined in figure 2.
To summarise, this system has one queue for each of the aforementioned microservices and each consumer is subscribed to one queue.
The queues are configured to listen for any messages with a routing key containing their own names (e.g. index, catalog etc.), with the exception of the worker, which instead listens for initial messages created by the API server, i.e. where the target is route, and any complete messages sent from other microservices after they have finished their processing and returned a message to the exchange.
Logging has also been implemented whereby each consumer will send a message with a routing key of nlds-api.log.[log_level], to be picked up by the logging consumer and logged into a separate file depending on which microservice it originated from.
Authentication
As previously mentioned, OAuth2 is being used to authenticate users to determine what files they can access and ultimately move between storage media. The message flow of this procedure can be seen in figure 3. This is currently implemented in NLDS with the password flow, whereby the user exchanges their password for an access token. In our case, the JASMIN accounts portal provides the token which is then stored in the user home-space. This token also expires after 24 hours, so the client will automatically attempt to refresh it if it has expired at the point of use.
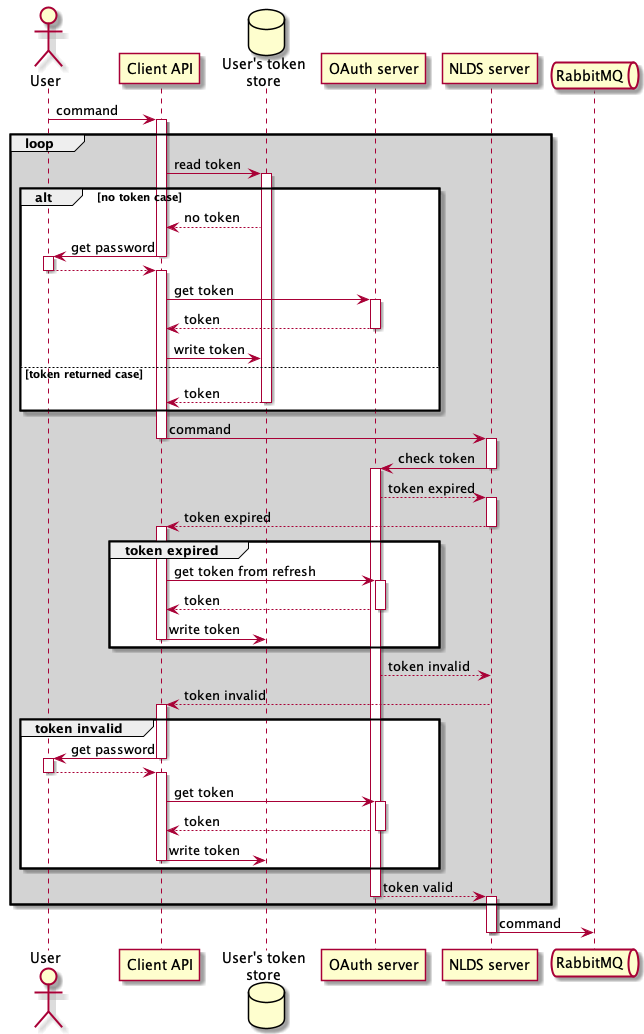
When the user attempts to then send requests to the NLDS-API using the client, the server will first check that this token is valid and, if it is, allow the request through to the exchange. This is achieved through a ‘plug-in’ authenticator class for JASMIN authentication, but has been written in such a way as to easily allow alternative authentication systems to be implemented (e.g. Google, Apple etc.). This is therefore, as previously stipulated, fully portable.
Note that the password flow is deprecated, so this will not be used in the final product.
Docker and Kubernetes
A key part of the current state of play is how the application has been deployed. We are keeping in line with modern dev-ops practices and deploying the server-API and the microservices on Docker containers via Kubernetes. Containerising the applications is standard practice at CEDA and allows for maximum portability, as it necessarily results in a pared-down, independently-runnable product.
Utilising Kubernetes provides many advantages, well documented elsewhere, but we will list here a few reasons it is particularly important to the NLDS:
- Zero-downtime upgrades: Updates to the software or configuration can be applied in a rolling fashion so that the service as a whole is ‘always up’. Users need not be inconvenienced at all.
- Dynamic redeployment: A crucial advantage of the microservice design, this is the ability to deploy more pods (i.e. consumers) under high-load.
- Liveness probes: Automatic and continuous checking of the containers to ensure that breakages are caught and acted on quickly, instead of being discovered through the support tickets of disgruntled users.
The Kubernetes deployments are managed by helm charts, making them standardised and version controlled. It should be noted though that the choice of Kubernetes as a deployment option somewhat limits portability, as Kubernetes is not a universal deployment option. Additional deployment pipelines are therefore being investigated.
Next steps
Good progress has been made in implementing the design set out in the design section, but much is still left to be implemented, the progress of which has been formalised into a series of milestones.
The first milestone was the implementation of a minimum viable product – a whole workflow whereby the user can successfully use the client to generate get/put requests and authenticate; the server successfully receives these requests, checks the authentication, and passes it to the message broker; and the queue system is able to process this message a minimum extent that the file or file-list requested can be indexed successfully. If you’ve been following closely, you’ll notice that this milestone corresponds to the current progress as laid out in the current progress section. The astute amongst you will now also realise the purpose of this blog post.
Further milestones have also been set for similar points in the applications lifecycle. The next milestone involves implementing the transfer microservice/processor such that files can actually be moved from disk to object storage. It will therefore have been achieved when just such a transfer has been made. A third milestone has also been envisaged for when the catalog has been properly implemented, and the GET command can therefore be used to actually retrieve files from object store. These have (loose) deadlines of the end of March and the end of May, respectively.
Further, less well defined, milestones are also in the works, with the implementation of monitoring a key element. Also necessary will be:
- Creation of the policy managing movement of files from warm to cold storage, with related goals of implementing a tape interface and showcasing that it works to follow
- Integration- and system- testing
- Containerisation of the rabbit server
- First deployment independent of CEDA architecture, showcasing portability
- Preparing and showcasing a one-click docker desktop deployment
None of which have a firm deadline. Yet.
Summary
A successor to the JDMA has been presented, which aims to better its predecessor by being portable, implementing CRUD, and being a single interface for hot, warm and cold storage. It will be comprised of a client, an API-server and a microservice layer, to allow better long term maintainability through modularity and robust service through scalability. This currently exists as a minimum viable product through which authenticated indexing of files can be requested via the command line. More functionality will be implemented in the coming months, which will be documented through further blog posts.
Acknowledgements
NLDS was supported through the ESiWACE2 project. The project ESiWACE2 has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 823988.
Software Stack
- nlds - The NLDS server and microservices
- nlds-client - The NLDS command line client
- FastAPI
- RabbitMQ