Smolagents is a simple python library developed by Hugging Face, that enables large language models (LLMs) to take control of workflows through agents. Agents offer a flexible way to handle tasks where traditional programming logic might not suffice, such as responding to complex queries or dynamically managing user interactions.
For instance, imagine a user poses a highly nuanced question requiring a search through an extensive document repository. Such a query might be too intricate for hard-coded logic but can be tackled by an agent equipped with tools for searching documents and generating responses using an LLM.
In this post I’ll explore Smolagents with an easy guide to setting it up, debugging it and some examples. Also, I will provide useful links to Smolagents tutorials made by Hugging Face.
What Won’t Be Covered
I will not be delving into the detailed use of transformers (Hugging Face’s way to download LLMs) or fully custom LLM models. However, I will briefly discuss how to use Ollama to download and run a local LLM with an agent.
While I will highlight some free LLM options, exploring the full specifications of each model is beyond the scope of this guide. If you’re interested in more advanced techniques, this guide at huggingface.co provides in-depth information.
Index
- Setup
- Agents And Their Applications
- Tools
- Simple Example
- Debugging
- More Complex Example
- My Thoughts And Findings
- Conclusion
- Sources And Further Information
Setup
Before diving into Smolagents, let’s ensure we have everything ready. In this section, I’ll cover the essential setup steps, including installing the required libraries, obtaining an API token, and logging in securely.
Prerequisites
You will need an API token from Hugging Face to use the LLMs. First, create an account with Hugging Face, then you will want to generate a fine-grained token on the tokens page.
Keep note of your API key as you will need it later.
Next open python and run pip install smolagents in your terminal.
Other installs should you need them: the top two are used in examples. You may also need torch (Pytorch) the final two are for optimisations should you want to go further.
pip install huggingface_hubpip install langchainpip install torchpip install bitsandbytespip install accelerate
Available LLMs
There are many different LLMs available on Hugging Face, some of which are “gated models” that require a subscription with Hugging Face (with exceptions like Llama). Below is a non-exhaustive list of free LLMs I’ve found and used in the examples later:
- Qwen/Qwen2.5-Coder-32B-Instruct This Qwen model has 32.8B parameters and is optimised for coding tasks, ideal for handling complex workflows.
- meta-llama/Meta-Llama-3-8B-Instruct A general-purpose LLM with 8B parameters.
- meta-llama/Llama-3.3-70B-Instruct A 70B parameter model suitable for searching large repositories of documents to answer user queries due to its large context length. However, as I was writing this it became a subscription model on Hugging Face.
- meta-llama/Llama-3.2-11B-Vision-Instruct A text-to-image model that also supports chatbot queries, though I recommend using a different model for general chatbot use.
For the Meta LLMs, you’ll need to agree to their community license agreement by providing your name and affiliation (as well as other optional information). Once submitted, your request will be processed automatically every hour.
If you prefer not to use a Meta LLM, the Qwen model is a great alternative and worked well in my tests.
Securing Your API Token
It’s important not to leak your token as your private repositories on Hugging Face could be accessed. To keep your token secure, storing it in a JSON file and accessing it programmatically in Python is a good practice. You can also add this JSON file to .gitignore to ensure it’s excluded from version control.
Here’s how you can set it up:
Inside the json file, which we will name api_keys.json
{"HF_ACCESS_KEY": "YOUR_TOKEN"}
And inside the Python file containing any agent using Smolagents.
import json
import requests
from huggingface_hub import login
# Read HF_ACCESS_KEY into hf_access_key
with open("api_keys.json", "r") as file:
hf_access_key = json.load(file).get("HF_ACCESS_KEY")
# Login to HuggingFace
try:
login(hf_access_key)
except requests.exceptions.HTTPError:
raise SystemExit(“Could not login to HuggingFace with access key”)This code logs you into Hugging Face, allowing you to use an agent without directly supplying it with a token inside the Python file, the examples below will assume that you have done this.
However, you can also parse the token into the model directly if you need to using: model = HfApiModel(model_id=model_id, token=token). I will explain the purpose of model later.
Starting the model with Smolagents (API)
The following is an example of how you would setup the model (which I will show you how to use in a later section) using the API method discussed above using the Qwen model.
For this code to work you will need the above code (alternatively you can parse in token=”YOUR TOKEN”, but I don’t recommend it outside of testing how Smolagents works).
from smolagents import HfApiModel
model_id = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = HfApiModel(model_id=model_id)You choose your model from Hugging Face’s available models and use HfApiModel to utilise it.
Important Notes
- Smolagents is an experimental library and may change over time.
- Outputs can vary as APIs and models evolve, so results may not always be consistent.
- It seems models can’t be too large when using the API, the following error can be produced:
too large to be loaded automatically (688GB > 10GB).
Using Local Models
When working with Smolagents, you may prefer using a local LLM instead of an API-based one for a variety of reasons from privacy to the cost of using an API. In this section I will briefly go over my experiments with Ollama.
What is Ollama?
Ollama is a local runtime environment designed to simplify using LLMs on your machine. It allows you to download, manage, and run various open-source models without requiring an account or internet connection for basic operations.
Getting Ollama
-
Visit the Ollama webpage and download the version for your operating system.
-
Run the downloaded app and follow on screen instructions. It will ask for administrator permissions. It will, at the end, display a command to download an LLM, you don’t need to run that if you are choosing your own.
Once you have it installed you can browse for models in Ollama which there are a lot of. I went for Llama3 so that will be the example I use, but I assume that the agent will work with any model.
You will then see a page that looks like this:
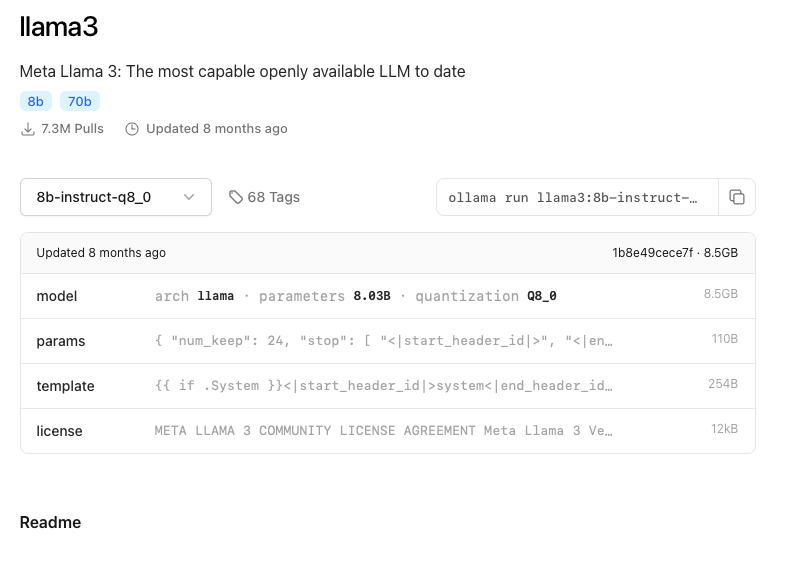
Using the dropdown menu press View all. From there you can choose which version you want to use (in my example 8B or 70B parameters). Along with the parameters it will also say what the quantisation level is (q number), which is a measure of how compressed the LLM is. The higher the q number the better the LLM will be, the low q numbers are for low-powered computers and the q number can go up to 8. Next to each model will also be a size in GB for it.
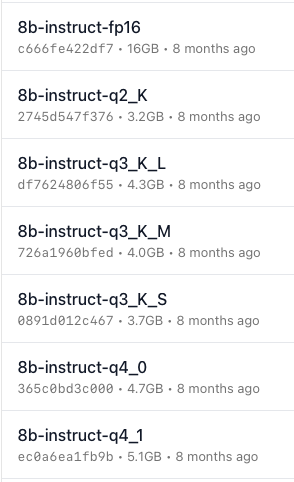
I settled on this model. You then copy the ollama run command to the right of the model select and run it in the command line, so I ran ollama run llama3:8b-instruct-q8_0. If it says ollama command not found, make sure Ollama is running and installed.
After a brief install (depending on the model size) you will have your chosen model installed!
After this step you are ready to start using Smolagents with the local model however. I am aware that there are more complicated things you can do with Ollama such as set it up on a server, but I won’t be going over that here. There is more information on this in the sources and further reading section.
Starting the model with Smolagents (Ollama)
The following is an example of how you would setup the model (which I will show you how to use in a later section) using the Ollama method discussed above using the Llama3 model. When using Ollama you do not need to login using your Hugging Face API key.
from smolagents import LiteLLMModel
model_id = "ollama_chat/llama3:8b-instruct-q8_0"
model = LiteLLMModel(
model_id=model_id,
num_ctx=8192
)You choose your model from Ollama’s models and use LiteLLMModel to utilise it. This method is slightly more complicated than using the API as there are a couple of extra parameters (more information here).
num_ctx determines how many tokens the model can consider when generating the next token. The Ollama default of 2048 is normally not enough. 8192 works for easy tasks, more is better. To calculate how much VRAM this will need for the selected model use this link from Hugging Face.
When I was using this model type with tools (explained later) I discovered that it didn’t like using tools that use the decorator @tool but instead worked when using the class method for tools which I found a bit strange.
Performance Notes
The simple way I set up the model on Ollama and the lightweight model I chose meant it struggled to run multiple agent interactions at the same time. For example, I ran the same python file multiple times and timed it. It went through each step in a round-robin approach, taking roughly the same amount of time as if each step ran sequentially. I’m sure there’s a way to improve it, but that is beyond the scope of this blog.
The model I chose was very RAM intensive. I am not sure how the Mac activity monitor works because I am more used to Windows Task Manager but from what I could tell it used about 4GB of ram when it was running the agent and the memory pressure went up quite a lot.
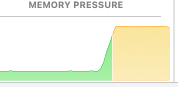
The model itself was also not very fast, this is most likely because the computer I used didn’t have a good graphics card meaning it had to mainly use the CPU.
Additional Notes
I watched a video about using Ollama with AnythingLLM and using the agents inbuilt in that which looked interesting (video)
Agents and Their Applications
Agents in Smolagents manage task execution by processing prompts and taking appropriate actions, such as calling tools or generating and executing code. Below are the agents Smolagents has to offer, each suited for different use cases. To understand the differences between the agents, read the agents documentation for Smolagents, and this guide provided by Hugging Face is helpful for building good agents.
Models are used in each Agent (except ManagedAgent), it is assumed that you have set up the model properly from the setup section. The models are what allow the agents to reason with human readable text.
MultiStepAgent
This is the Agent that ALL other agents inherit from meaning they can act in multiple steps, each step consisting of one thought, one tool call and execution. (MultiStepAgent guide)
For more information on what parameters this agent has please look here
A few useful parameters I have found are:
| Parameter | Description |
| ——— | ———– |
| max_steps | Sets the max number of steps the agent can run (default is 5), useful for weak LLMs or complicated tasks. |
| additional_authorized_imports | A list of imports the agent can use in any code it generates as well as what is already imported. |
| planning_interval | The interval an agent will run a planning step (consumes a step so good in conjunction with max_steps), the planning step allows the model to revise its list of facts and reflect on steps it should take based off them. |
The above parameters are all optional.
CodeAgent
The CodeAgent is the default agent and writes its tool calls in Python code. By default this is executed in your local environment, which means you may need additional installs for some queries.
Example:
from smolagents import CodeAgent
# model = one of the two methods discussed above in Setup
agent = CodeAgent(model=model, tools=[])
agent.run("Calculate the square root of 256.")For more information on what parameters this agent has please look here.
ToolCallingAgent
This agent writes and suggests JSON-based tool calls instead of executing code directly. If this agent type doesn’t work, try using CodeAgent.
Example:
from smolagents import ToolCallingAgent, tool
# model = one of the two methods discussed above in Setup
# This tool type will not work with the Ollama model method discussed above, use the second type of tool discussed below
@tool
def greet_tool(name: str) -> str:
"""
This tool returns a string greeting the name inputted into this tool
Args:
name: The name of the person to greet
"""
return f"Hello, {name}!"
agent = ToolCallingAgent(model=model, tools=[greet_tool])
agent.run("Greet John")For more information on what parameters this agent has please look here.
ManagedAgent
Manages an agent and provides additional prompting and run summaries. This is more complicated than the two above as this wraps an agent giving it a name and description and allows a CodeAgent to run use it.
Example:
from smolagents import ManagedAgent, ToolCallingAgent, CodeAgent, DuckDuckGoSearchTool
# model = one of the two methods discussed above in Setup
@tool
def visit_webpage():
# This tool type will not work with the Ollama model method discussed above, use the second type of tool discussed below
# Basic ToolCallingAgent with search tools
web_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool(), visit_webpage],
model=model,
)
# Wrap the searching agent in ManagedAgent
managed_web_agent = ManagedAgent(
agent=web_agent,
name="search",
description="Runs web searches for you. Give it your query as an argument.",
)
# create the manager agent that can use the managed agent
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[managed_web_agent],
additional_authorized_imports=["time", "numpy", "pandas"],
planning_interval=3,
)
manager_agent.run("How tall is the Eiffel tower?")For more information on what parameters this agent has please look here.
GradioUI
Provides a nice looking UI for the agent (runs on a local URL e.g: http://127.0.0.1:7860).
Example:
from smolagents import GradioUI, CodeAgent
# model = one of the two methods discussed above in Setup
agent = CodeAgent(tools=[], model=model)
GradioUI(agent).launch()For more information on what parameters GradioUI uses please look here.
Tools
Smolagents supports two types of tools to extend agent functionality: decorator-based tools (@tool) and subclass-based tools. These allow agents to perform specific actions, such as interacting with APIs, performing data processing, or other customised tasks. Refer to the Tools documentation for additional details.
@tool decorator
The @tool decorator allows you to quickly define lightweight tools by wrapping a function. It’s ideal for simple tasks where no complex behaviour or state management is required such as creating a simple tool that only needs a function to produce results. More information can be found in the Hugging Face agents tutorial.
Example: Decorator
from smolagents import tool, ToolCallingAgent
model = # your prefered model from the setup section
@tool
def greet_tool(name: str) -> str:
"""
This tool returns a string greeting the name inputted into this tool
Args:
name: The name of the person to greet
"""
return f"Hello, {name}!"
agent = ToolCallingAgent(model=model, tools=[greet_tool])
agent.run("Greet John") # Output: "Hello, John!"}
- Descriptive names: Ensure the function name clearly indicates its purpose for the LLM.
- Type hints: Provide input and output type hints so the LLM understands expected data types.
- Docstrings: Include comprehensive docstrings with a description and uses
Args:to describe each argument.
Tool subclass
Subclassing Tool allows you to build more sophisticated tools with custom logic, giving you more flexibility and allowing you to use heavy class attributes. More information can be found in the Hugging Face agents tutorial.
Example: Subclass
from smolagents import Tool, ToolCallingAgent
model = # your preferred model from the setup section
class GreetTool(Tool):
name = "greet_tool"
description = "This tool returns a string greeting the name inputted into this tool"
inputs = {
"name": {"type": "string", "description": "The name of the person to greet"}
"other": {"type": "string", "description": "Another variable as an example"}
}
output_type = "string"
def forward(self, name: str, other: str) -> str:
return f"Hello, {name}!"
greet_tool = GreetTool()
agent = ToolCallingAgent(model=model, tools=[greet_tool])
agent.run("Greet John") # Output: "Hello, John!"The subclass method works in much the same way as the decorator method but with a few key differences in syntax.
- Attributes used instead of docstrings: Use
name,description,inputs, andoutput_typeto describe the tool. - Explicit input definitions:
inputsis a dictionary specifying each input’s type and description. - Custom logic via forward: Define the tool’s main functionality in the
forwardmethod.
I have also found that subclass tools are the only type of tool to work when I tried using Ollama, this may be fixed in a later update but while I am writing this it isn’t the case.
Which to chose?
Here is a table that can help you choose whether to use a subclass or decorator.
| Criteria | @tool Decorator | Tool Subclass |
|---|---|---|
| Simplicity | yes | no |
| Quick Prototyping | yes | no |
| Complex Logic | no | yes |
| State Management | no | yes |
Simple example
In this example, the LLM is given a tool for calculating the area of a trapezium. The tool keeps track of how many calculations have been performed and the cumulative area calculated. The tool is then used by a CodeAgent to perform the task.
from smolagents import Tool, LiteLLMModel, CodeAgent
class TrapeziumAreaTool(Tool):
name = "trapezium_area"
description = (
"Calculates the area of a trapezium given the lengths of the two parallel sides (a and b) "
"and the height. Keeps track of total cumulative area calculations."
)
inputs = {
"a": {"type": "number", "description": "Length of the first parallel side (a)."},
"b": {"type": "number", "description": "Length of the second parallel side (b)."},
"height": {"type": "number", "description": "Height between the parallel sides."}
}
output_type = "number"
def __init__(self):
self.calculation_count = 0
self.cumulative_area = 0.0
def forward(self, a: float, b: float, height: float) -> float:
if a <= 0 or b <= 0 or height <= 0:
raise ValueError("All dimensions must be positive non-zero numbers.")
# Calculate the area of the trapezium
area = 0.5 * (a + b) * height
self.calculation_count += 1
self.cumulative_area += area
return area
def get_calculation_count(self) -> int:
"""Returns the number of area calculations performed."""
return self.calculation_count
def get_cumulative_area(self) -> float:
"""Returns the cumulative area calculated so far."""
return self.cumulative_area
# Instantiate the custom tool
trapezium_area_tool = TrapeziumAreaTool()
# Create the agent (Ollama used, feel free to use other methods)
model_id = "ollama_chat/llama3:8b-instruct-q8_0"
model = LiteLLMModel(
model_id=model_id,
num_ctx=8192
)
agent = CodeAgent(tools=[trapezium_area_tool], model=model)
# Run the agent with prompts
agent.run("Find the area of a trapezium with a=5, b=10, and height=7.")
# If ran correctly then answer = 52.5Debugging
When using Smolagents, various issues can arise depending on the complexity of the tools, the model or agent you are using. Below, I’ve included some problems I have encountered and suggestions on how to address them.
Weak LLM Performance
Problem:
The agent may not perform well, it may be vague, incorrect or overly simplistic in its responses.
Cause:
The model powering the agent is not suited for the task you are giving it.
Solutions:
- Ensure the model you are using is powerful enough to handle the task you give it (e.g: a very lightweight model will struggle with very complex tools). You can estimate how powerful a model is by the number of parameters (the ‘B’ number). The higher the number, the more powerful the model.
- Ensure that the model you are using is suited to the task you give it, don’t use an image generator model as a generic chat bot.
- Increase the context size (
num_ctx), it may not be high enough to complete the task. - Refine the inputs or prompts to be clearer and more focused.
Not enough steps
Problem:
The agent runs out of steps before it finishes its task. This can happen if you have a complex task and not a very powerful model, the agent will use a lot of its steps failing to complete its task and may run out before it gets an answer.
Cause:
The default of 5 steps for the agent is not enough steps and should be increased.
Solutions:
- Increasing the
max_stepswhen creating an agent is the best way to remedy this. - Consider giving the agent a
planning_intervalif it still has problems.
Poor description
Problem:
The description in the tool is not detailed enough and the LLM strugles to know what the tool does.
Cause:
The description section in the tool may be improperly formatted or too vague.
Solutions:
- Put yourself in the LLM’s shoes-would you be able to understand what the tool did with the given information?
- Add more detail to the description.
- Add more type hints. Explicitly specify expected input and output types. Python’s typing module could be helpful.
For more ways to debug agents look here and inspecting agent runs here on the Hugging Face website.
More complex example
To summarise, in this section I’ll walk you through an example from Hugging Face’s tutorial about agents, which is a great demonstration of internal document searching.
In this example, a dataset from Hugging Face’s documents is loaded into source_docs. You can easily modify this to use any document, whether locally or remotely stored. The dataset is processed so that the tool can handle it. The agent is then able to search through the documents using semantic search to provide answers to the user’s queries.
It’s important to use a model with a large context size, especially when working with a large number of documents.
from dotenv import load_dotenv
load_dotenv()
import datasets
import json
import requests
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.retrievers import BM25Retriever
from smolagents import Tool, HfApiModel, CodeAgent
from huggingface_hub import login
# Read HF_ACCESS_KEY into hf_access_key
with open("api_keys.json", "r") as file:
hf_access_key = json.load(file).get("HF_ACCESS_KEY")
# Login to HuggingFace
try:
login(hf_access_key)
except requests.exceptions.HTTPError:
pass
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
knowledge_base = knowledge_base.filter(lambda row: row["source"].startswith("huggingface/transformers"))
source_docs = [
Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]})
for doc in knowledge_base
]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
add_start_index=True,
strip_whitespace=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = text_splitter.split_documents(source_docs)
class RetrieverTool(Tool):
name = "retriever"
description = "Uses semantic search to retrieve the parts of transformers documentation that could be most relevant to answer your query."
inputs = {
"query": {
"type": "string",
"description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
}
}
output_type = "string"
def __init__(self, docs, **kwargs):
super().__init__(**kwargs)
self.retriever = BM25Retriever.from_documents(
docs, k=10
)
def forward(self, query: str) -> str:
assert isinstance(query, str), "Your search query must be a string"
docs = self.retriever.invoke(
query,
)
return "\nRetrieved documents:\n" + "".join(
[
f"\n\n===== Document {str(i)} =====\n" + doc.page_content
for i, doc in enumerate(docs)
]
)
# instantiate the tool with the docs
retriever_tool = RetrieverTool(docs_processed)
# setup agent and model
model_id = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = HfApiModel(model_id=model_id)
agent = CodeAgent(
tools=[retriever_tool], model=model, max_steps=4, verbosity_level=2
)
# Very simple way to ask the agent questions without restarting the code
run = True
while run == True:
query = str(input("enter query: "))
if query == "end":
run = False
break
agent_output = agent.run(query)
print("Final output:")
print(agent_output)My thoughts and findings
I find that once you have set up a tool that is robust enough, the agent is able to use it with great reliability, particularly when the tool is simple. In terms of ease of use, while it can be challenging to setup and understand at first, it becomes relatively straightforward once you are familiar with it. The only issue I encountered, aside from debugging the agents, was Hugging Face changing which models were available to free API users. Because of this, I recommend using a local LLM to increase reliability further as shown in this section.
Conclusion
In conclusion, while setting up and configuring agents and tools may seem complex initially, once the foundations are in place, the process becomes more intuitive and reliable. The use of simple tools allows for effective and consistent results, especially when paired with the right model. However, issues like changes to API availability can disrupt the process, so relying on a local LLM could offer a more stable and controlled environment. Overall, Smolagents provides a powerful framework for building intelligent agents, and with proper setup, it can be a reliable tool for various tasks.
Sources and further information
Hugging Face Resources
- SmolAgents Blog
- SmolAgents Guided Tour
- Building Good Agents
- Tool Calling Agent Reference (v1.4.1)
- Multi-Agents Example
- Agents Reference
- Agents Reference (v1.6.0)
- Tool Reference (v1.6.0)
- Inspect Runs Tutorial
- RAG Example
- VRAM Calculator
- Transformers Documentation
- Hugging Face Models
LLMs on Hugging Face
- Qwen2.5-Coder-32B-Instruct
- Llama-3.2-11B-Vision-Instruct
- Llama-3.3-70B-Instruct
- Meta-Llama-3-8B-Instruct
YouTube Tutorials
- SmolAgents Overview (API)
- SmolAgents Overview (Ollama)
- Ollama tutorial
- Ollama with AnythingLLM
- Smolagents tutorial
Ollama
- SmolAgents Guided Tour (Ollama)
- Ollama FAQ: Concurrent Requests
- Ollama Server-to-Server Discussion (Reddit)
- Ollama Parallelism (Stack Overflow)