 Daniel Westwood
Daniel WestwoodSTAC (Spatio-Temporal Asset Catalog) is a widely adopted standard for metadata records within the Earth Observation community and beyond, created as a standardised way to expose collections of spatio-temporal data. For several years, the Centre for Environmental Data Analysis (CEDA) team has been working towards a STAC-based metadata catalog to represent our data holdings within the archive. A key innovation for the CEDA catalog has been the inclusion of a CMIP6 data profile into STAC, an important step towards bridging the gap between Earth Observation and Climate model datasets.
DataPoint is a package developed at CEDA to provide key features for improved search functionality across the CEDA STAC catalog, as well as integrating known cloud-optimised formats for effective access to analysis-ready data. In this article we discuss the inspiration for creating DataPoint and its impact for the user community, as well as the strategic direction for CEDA towards cloud-enabled data processing.
The CEDA STAC catalog has become part of the Earth Observation Data Hub (EODH) project led by the National Centre for Earth Observation (NCEO).
Index
- Acronyms
- Cloud Optimised Formats for Data
- Inspiration
- DataPoint API Features
- Current CEDA STAC Collections
- Next Steps
- Getting in touch
Acronyms
| Acronym | Meaning |
|---|---|
| STAC | Spatio Temporal Asset Catalog |
| CMIP | Coupled Model Intercomparison Project |
| WCRP | World Climate Research Project |
| ARD | Analysis Ready Data |
| EOCIS | Earth Observation Climate Information Service |
| EODH | Earth Observation Data Hub |
| OPeNDAP | Open-source Project for a Network Data Access Protocol |
Cloud Optimised Formats for Data
Over the last few years the CEDA team have been creating workflows to generate new cloud-optimised data representations at-scale, using open-source tools like Kerchunk and Zarr. These tools have been developed to enable greater access to large sets of data traditionally stored in data archives that require knowledge of the posix filesystem and access methods in order to make use of the data. Cloud-optimised data representations open the door to greater interconnectivity between data centres and fewer physical and technical barriers to research requiring data analysis. This represents the latest step towards subsetting and aggregating data for optimised remote workflows, following projects such as OPeNDAP which enables HTTP range requests to access subsets of data in NetCDF and other formats.
The Kerchunk reference specification, used to produce “Virtual” zarr stores enables similar range-based HTTP access to archival data, condensed into a single reference file which serves as an access layer on top of the existing dataset. Chunk-based references are stored using JSON and can be used to construct an Xarray Dataset, using Dask for lazy data loading. By comparison, the Zarr format splits data chunks into individual binary files, with an attached metadata file that can be used with the Zarr API. CEDA focuses specifically on data representations/references using Kerchunk, where duplication of data for cloud-based storage is minimised, as public cloud storage can often be expensive and constitute a considerable additional carbon cost.
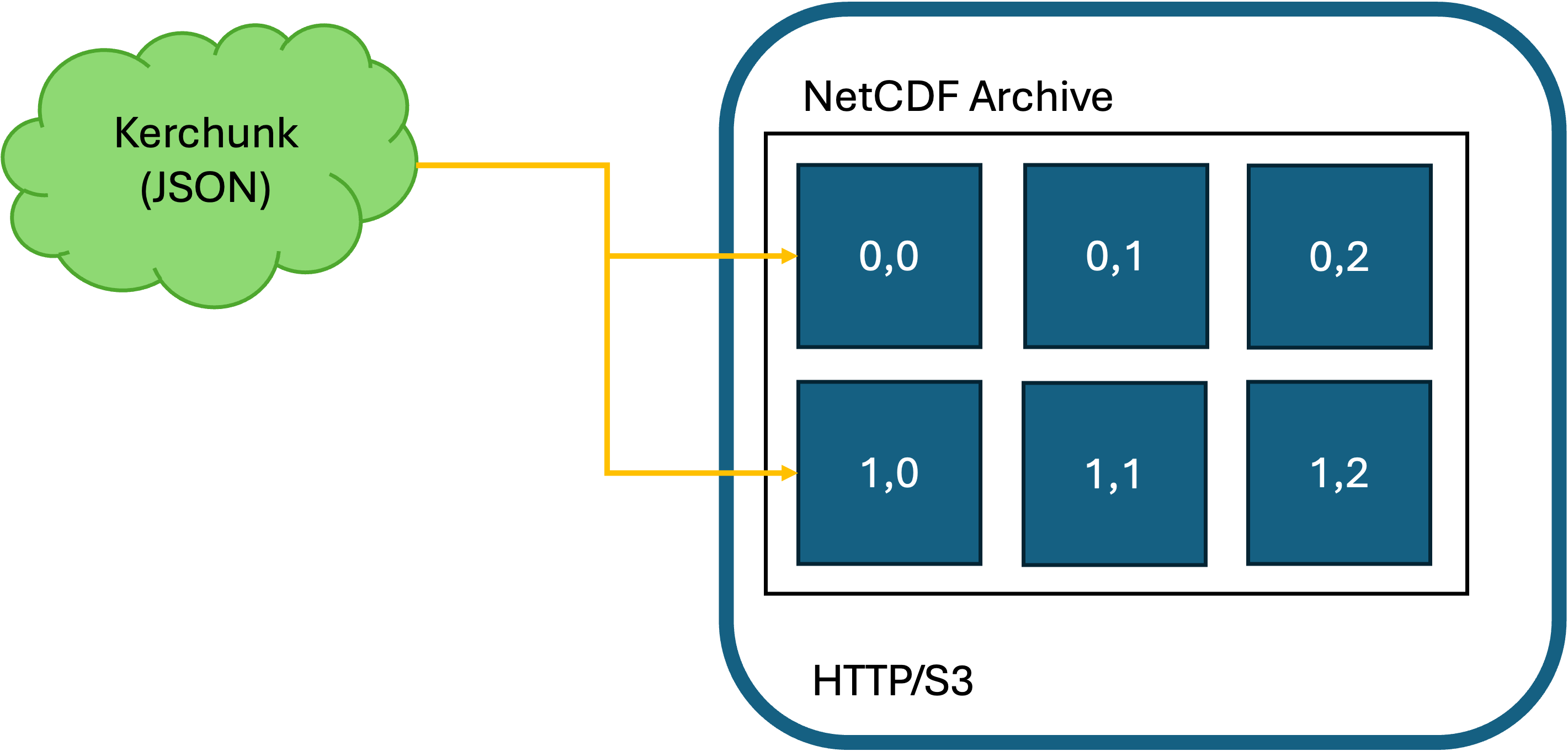
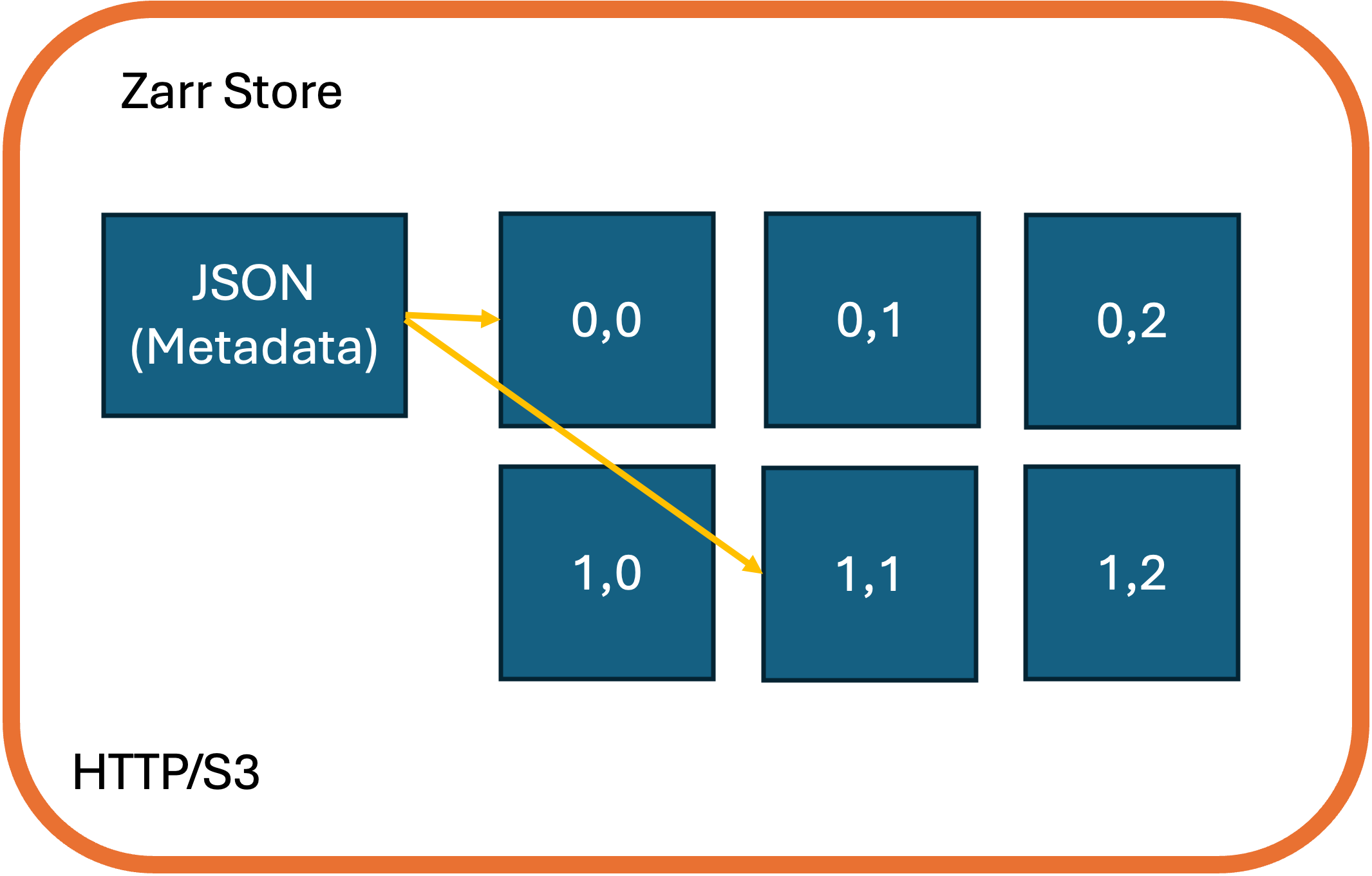
These new data representations have been ingested into the CEDA Archive and are accessible to all users, however since these technologies are relatively new to most user communities the mechanisms for accessing these types of data are unfamiliar and not widely known. Researchers using our data are more familiar with well-established formats like NetCDF/HDF which have existed for several decades as standards for data archival. What has been missing is a collation of these technologies into a single client-side tool that CEDA can direct users towards, and focus efforts towards improving data access across all new developments.
Inspiration
Why did we create DataPoint?
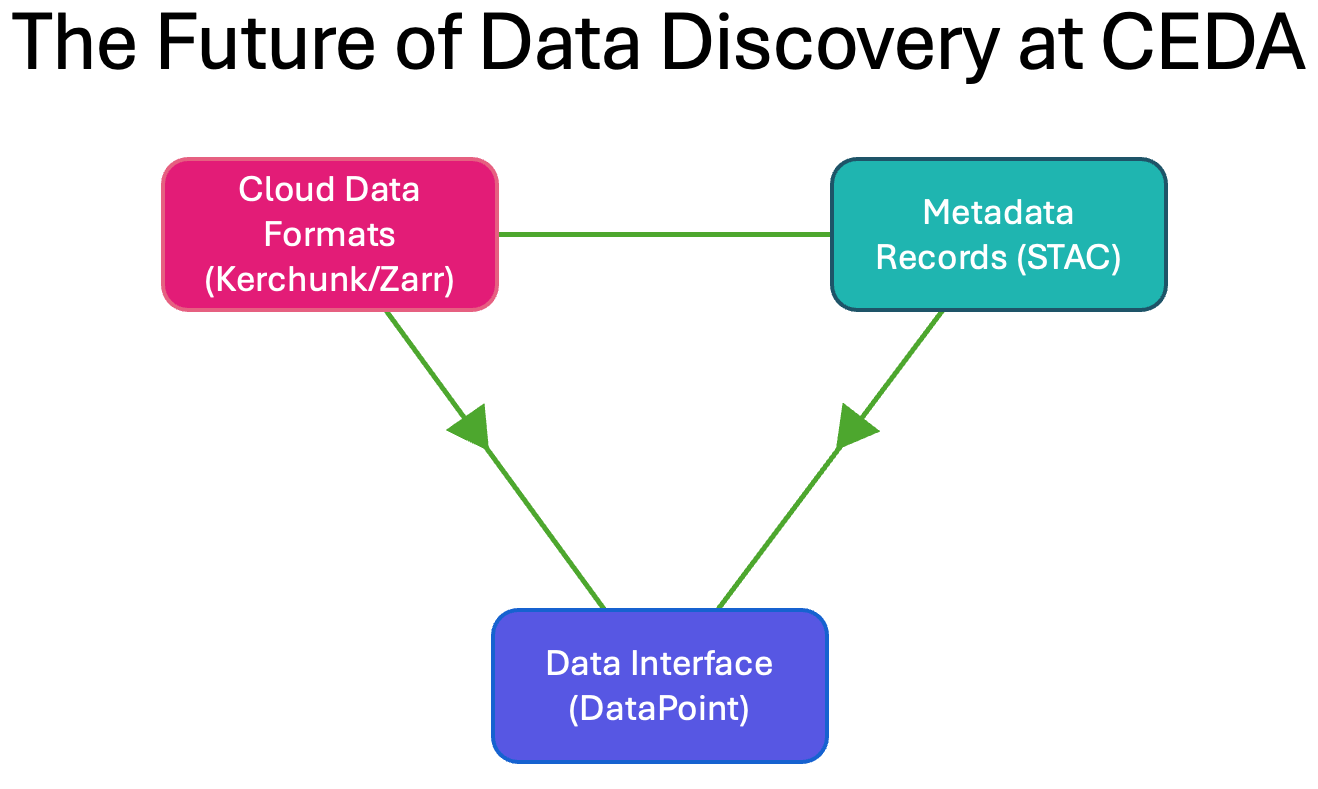
DataPoint is the culmination of several projects involving the creation of a single point of access to the data archived at CEDA; the so-called ‘CEDA Singularity’. It is a STAC-based API client which connects to our STAC catalogs and can be used to search across our data holdings to find specific datasets and metadata. What sets DataPoint apart is the ability to directly open datasets from cloud formats without the user needing to understand the format or specific configuration for opening the dataset.
Other similar technologies exist which can build data representations using cloud-based API endpoints. For example in the Earth Observation community there is a python client called openEO which focuses specifically on enabling cloud-based processing and workflows through openEO backends that a user can connect and arrange processing tasks. There is however a lack of a tool for seamless client-side data access to simply handle the configurations of STAC in a simplified way. DataPoint is intended as a tool for reducing the complexity of loading data from STAC using cloud-based technologies.
Why should you use DataPoint?
At the time of writing this article, DataPoint should be considered a non-production package, meaning that it is not advised to solely rely on DataPoint for all data analysis use cases. While the syntax and usage of DataPoint is unlikely to change, the STAC catalog infrastructure is likely to be updated and improved on an ongoing basis, which may cause changes to observed search results with the current package.
The best and most encourageable use case for DataPoint for the time being is for quicklooks and brief analysis of data within the STAC catalog, as well as its use as a data locator. Users are advised to identify key parameters of the dataset they are accessing (i.e item identifier or path to data files), to ensure reusability of any data analysis methods being performed. Future DataPoint updates will involve enabling easier sharing and saving of searches which are reusable and fit with the FAIR data principles.
With that being said, now is a great opportunity to start using DataPoint for locating and quickly accessing data within CEDA as this method of data retrieval is becoming increasingly common within the wider climate data landscape. User-provided feedback can directly impact new feature releases on a short timescale as this project is in active development, especially since this is a CEDA-developed package which mostly caters for CEDA-centric use cases. The CEDA DataPoint API has now been added to the JASMIN Standard Computing Environment (JASPY) Module.
To summarise:
- DataPoint is developed directly by CEDA to serve the user community, so CEDA-centric use cases can be catered for directly with features requested by the community.
- API-based/cloud-native data access is becoming increasingly common - why not start with DataPoint?
DataPoint API Features
DataPoint has been designed with scientific research use cases in mind - with encouragement for feedback from the user community at every stage that can be incorporated into new feature releases for DataPoint. Highlighted here are some of the features added to DataPoint that are specifically aimed at improving the user experience of finding and accessing data.
Abstraction of the POSIX Filesystem
STAC assets within the collections that are accessed by DataPoint have a reference to the exact data path within the CEDA archive where specific files can be found. This is used within DataPoint to locate the specific STAC asset, without the user needing to know the location of relevant datasets themselves. The creation of data cubes (objects that contain metadata about the datasets) is seamlessly abstract, such that no user-supplied information should be necessary, beyond the search parameters needed to identify the correct dataset. This represents a shift from a file-based to a more intuitive variable-based mindset, where users can access a time-series for a given variable or array index, rather than rely on a set of files. DataPoint does however ensure that the set of assets can be extracted as a list for any given dataset - if users prefer to locate the files themselves.
Format-Agnostic Data Handling
Where DataPoint objects have been created to represent specific datasets, these objects have the capacity to access and serve data directly, again without user configuration required. The format of the data and storage configurations do not need to be known to the user; you do not need to know that the data is stored as Cloud-Optimised GeoTiff (COG), Zarr or any other format. DataPoint knows how to open them for you - this is currently supported for cloud-based formats/specifications like COG, Zarr and Kerchunk, but in future will be extended for other file types like NetCDF/HDF, CSV, etc. An example of how to extract an xarray-based data representation from a given STAC item (regardless of format) is given below:
from ceda_datapoint import DataPointClient
client = DataPointClient()
search = client.search(collections=['cmip6'],max_items=10)
# The search can render a list of the available data assets given this search criteria.
xr_dataset = search.open_dataset('CMIP6.ScenarioMIP.THU.CIESM.ssp585.r1i1p1f1.Amon.rsus.gr.v20200806-reference_file')
In general, users are advised to collect cloud assets into a cluster, rather than opening a dataset directly from the search object.
Single-Search Selections
The selections made via the pystac-based DataPoint search, are now applied directly to the data where possible. This minimises the extra configuration required to get to your specific spatial/temporal area of interest (AOI). The following search parameters are now applied directly to the data as standard:
-
intersects: Search query for accessing STAC records within a specific AOI, this area will then be applied to the data produced when performing
open_datasetso your data cube is representative of the search specified. (Note: This is supported for standard regular-grid coordinates only - namely lat/lon or variations of those. This is an experimental feature, please report any issues on the GitHub repo - link above) -
datetime: Search query for finding STAC records that fall within a datetime range. This range is then applied to the data cube/array on output. (Note: This is supported for the standard temporal dimension label
timeonly. Arrays without atimedimension are not applicable. This is an experimental feature, please report any issues on the GitHub repo - link above) -
query.variables: Pystac implements a metadata query parameter for searching specific fields in the STAC properties. For STAC records that contain a
variablesproperty, this search is applied directly to the data array on output, so your dataset contains just the variables you’re searching for. This feature can also be utilised via thedata_selectionsparameter specific to DataPoint - see below.
An example query where the single-search selections will be applied is shown below. In this case an example collection is being queried to find a specific area of interest (GeoJSON AOI), within a given datetime window. Specifically this collection uses the CMIP6 schema for metadata attributes, and we have identified the Sea Surface Temperature (SST) as the intended variable. Note that the duplication of the variables attribute is not necessary in most cases where the variable forms part of the STAC metadata.
>>> client.search(
collections=['example_collection'],
intersects={
"type": "Polygon",
"coordinates": [[[6, 53], [7, 53], [7, 54], [6, 54], [6, 53]]],
},
datetime='2025-01-01/2025-12-31',
query=[
'cmip6:experiment_id=001',
'variables=sst'
],
data_selection={
'variables':['sst']
'sel':{
'nv':slice(0,5)
}
}
)
Current CEDA STAC Collections
The CEDA STAC API server is still in a pre-production stage, subject to change as the collections are updated and metadata is revised. As of the publication of this article there are 17 top-level collections via the main CEDA API, with CEDA-developed CCI collections being constructed in a separate location as part of the Knowledge Exchange programme. For more details regarding CCI data, see the ESA Climate Office’s Open Data Portal
Some specific collections include cmip6 (CMIP Phase 6, provided by WCRP), CORDEX and various sentinel-based collections describing ARD products, which has been arranged in partnership with EOCIS. These STAC collections will be expanded over time, and are exposed for active use within EODH, detailed below.
Earth Observation Data Hub
The Earth Observation Data Hub project aims to develop and operate a new centralised software infrastructure to provide a new ‘single point’ of access for UK EO data offerings from distributed public and commercial centres. This includes data held both by CEDA on behalf of NERC/NCEO and other groups, as well as commercially sourced data from companies like Airbus. Part of the Data Hub includes both a STAC-based catalog and API client tools for data access. The catalog hosted by EODH is partially constructed from the CEDA STAC catalog, with the addition of data from other sources, so any data hosted by CEDA will appear in the EODH for use with any cloud-based applications deployed on the hub. A link to the data hub can be found in the further resources section of this article - the Hub project has begun development of the second phase, following the success of the pathfinder phase in year 1.
Additionally, one of the API client tools provided by Oxidian as part of the Hub toolkit - pyeodh - operates similar functionality to DataPoint. Elements from the DataPoint package (such as the CloudProduct module) are used within pyeodh to ensure widespread use of the cloud-based formats available through the catalog, and further expand the use case of DataPoint. This package is still in early development, so feedback to both pyeodh and DataPoint are strongly encouraged.
Next Steps
Feedback from Living Planet: FAIR Data
The ESA Living Planet Symposium was hosted at the Austra Center Vienna conference centre from 23-27 June 2025. A presentation of DataPoint was given during the session entitled “Advancements in cloud-native formats and APIs for efficient management and processing of Earth Observation data” to an audience of data scientists, researchers and technical developers. The presentation will be published as part of the Living Planet proceedings publication and should be visible at https://lps25.esa.int/.
Overall the response to the DataPoint package was positive, with some specific questions around long term support for the package and its use in scientific research. While DataPoint provides some very useful functionality for optimising data access and ease-of-use, none of the data processing is solely dependent on the use of the package against any other means. DataPoint simply takes advantage of the existing infrastructure within CEDA to provide better access to data, where other means exist but are more cumbersome and require greater manual configuration.
With that being said, the question of reusability and repeatability is something that will be taken into account in future DataPoint updates, specifically how a given set of data provided by a search can be represented in some way that can be preserved and maintained for future users. This should be made infrastructure-independent as far as possible, such that even if DataPoint and other dependencies are at some point decommissioned, the data is still clearly findable and accessible in the long term. In other words, considerations should be made such that DataPoint provides data under the FAIR data principles, which includes the reusability of both datasets and data workflows.
Increased STAC Catalog Coverage
Works are ongoing within CEDA to expand the current STAC holdings that represent the archive to encompass more data. This includes the UK Climate Projections (UKCP) and Coupled Model Intercomparison Project (CMIP6/7), both of which have some limited STAC representation at present. DataPoint will continue to be promoted as a core package for use on JASMIN to access data in the CEDA Archive, and there is considerable desire to incorporate other projects and datasets into this model of data access.
Getting in touch
If you would like to discuss this topic or other questions related to data Storage, Access and Discovery, please contact Daniel Westwood by email.
Github Repositories and Documentation
- CEDA DataPoint Github
- DataPoint Documentation
- pyeodh Github Repository
- openEO Documentation
- STAC Specification
- Pystac Client Documentation
- Kerchunk Documentation
- VirtualiZarr Documentation