We have been looking around for a flexible, scalable standard which would allow us to expose the bulk of the CEDA archive via faceted search. This could then be used to build user interfaces and enhance search services at CEDA. Here, we consider the feasibility and suitability of STAC and discuss progress into an Elasticsearch-based implementation.
Index
- Background
- Requirements
- Proposal
- STAC Thoughts
- Progress So Far
- Where next?
- Conclusion
- Software Stack
Background
CEDA is a national data centre for atmospheric and earth observation research. We host over 15 Petabytes of atmospheric and earth observation data. Sources include aircraft campaigns, satellites, automatic weather stations and climate models, amongst many more.
The CEDA archive is comprised of mostly netCDF data but we also have other formats including data where the format is not immediately obvious from the file name and extension.
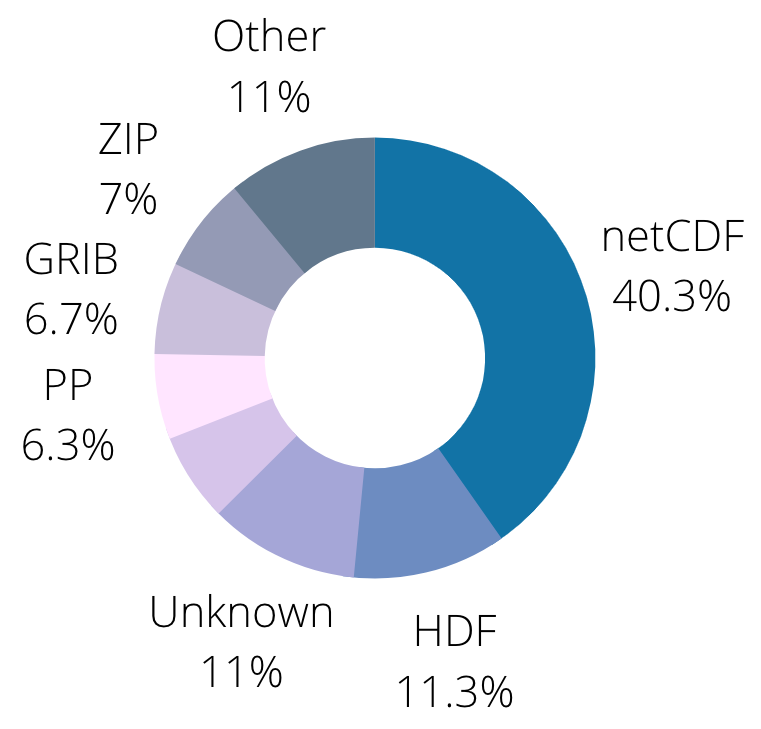
Although there are data standards, these standards vary through time and across different domains. This leads to a heterogeneous archive with legacy formats and structures, presenting an indexing problem.
The current state of search and discovery comprises of two main services:
- CEDA Catalogue - a hand-crafted store of information about each dataset (in a relational DB)
- Archive Browser - a directory-based browser with links to the catalogue and download services
Powering search, the catalogue uses the Django Haystack plugin to provide text-based and limited faceted search using Elasticsearch. An Elasticsearch index sits behind the Archive Browser and stores all the files and directories in the CEDA archive.
As part of the ESA CCI project (European Space Agency Climate Change Initiative), we replaced a complex system comprising of a CSW, Solr and ESGF-Search API, with a single Opensearch API (not to be confused with “Opensearch” Amazon’s open source Elasticsearch fork).
Our Opensearch endpoint brings together the information previously served by multiple endpoints along with search and discovery through the description document. Best practice, collected and preserved in the CEOS best practice guide, informed the development of this service and it underpins data access and visualisation for other project partners.
Although the Opensearch standard has existed since 2005 and browsers even support the standard to provide site search from the address bar, it is not common in the Earth System community. There has been some adoption within the Earth Observation community (i.e. CEOS) but there doesn’t seem to be much of a community surrounding it with a set of interoperable tools.
Requirements
When thinking about what we would like/need from search we came up with a wish list:
- Community-driven stardard with re-usable tools and clients for accessing
- Flexible enough to cope with the heterogeneous nature of the CEDA Archive
- Free-text queries
- Faceted search to narrow search parameters
- Capable of supporting mappings between different vocabularies used by scientific domains
- Search across data holdings to identify similar data, even if you might not have already been aware of it
- Self-describing. The API should be flexible and self-describing so a client does not need to have a priori knowledge to interact
- Scalable indexing solution to handle the growing archive
- Flexible enough to be adopted by other similar archiving facilities and federations
- Foster collaboration with other interested parties
Proposal
One of the latest buzzwords in the EO community is STAC.

STAC (Spatio Tempoal Asset Catalog) provides a well defined, developer friendly JSON API which defines the minimum specification to describe and search geo-spatial assets. The core spec requires space and time on a lat,lon grid in a normal 365 day calendar. This core is extensible and there are now many community extensions. The standard was developed with the Earth Observation community as the primary beneficiary for the API.
As members of the Earth Observation, Atmospheric Science and Earth System Modelling communities as well as for our own interests, we are interested to see whether STAC can fit our needs.
STAC Thoughts
In the Earth System Modelling community, there have been discussions surrounding where the datasets fit into the STAC paradigm. When we were first looking at STAC we started with the idea that time series datasets would be a Collection-level Asset. This was to provide scope to create searchable, smaller chunks as Items (i.e. Time steps), however the ability to sub-divide the assets will depend greatly on the aggregated object. This is made more difficult by the different data storage formats which exist. A time-series made up of a lot of individual netCDF files might make sense as Items with an aggregated object at the Collection level. Each file is stand alone. Changing to use Zarr formatted data (Zarr newbie so correct me if I am wrong, but..) the individual zarr objects cannot be used on their own and require their parent, Zarr store object to be useful.
As Zarr and netCDF both allow lazy loading and subsetting with their clients, I am not sure there would be the need or you could pass the Asset list to a WPS service to provide you a subset (gradually becoming a substitute for OPeNDAP). At CEDA we have come to the understanding, one which seems to be supported by statements in the stac-spec, that the STAC types break down into:
-
Collection - A group of objects which can be described by a common set of “facets”. e.g. CMIP5, Sentinel 3, FAAM
“The STAC Collection Specification defines a set of common fields to describe a group of Items that share properties and metadata.” - collection spec)
-
Item - An individual meaningful object that scientist would want to find and use. This could be a single satellite image in the EO context, but in the ESM context (such as CMIP6), it could be a time-series for a single variable simulated for a given model, experiment, realisation, realm and grid. The latter is typically saved into a single Zarr store when written to Object Store.
-
Asset - “An Asset is an object that contains a URI to data associated with the Item that can be downloaded or streamed. It is allowed to add additional fields.” - Asset Spec
This approach works nicely with item-search as you could search for your datasets with the current API specification. As collections provide an aggregation of item properties within the “summaries” attribute, you could see that collection search could be really useful to find parents of similar data and could massively reduce the search result clutter when querying 100,000s or 1,000,000s of items.
Progress So Far
At CEDA we are coming from the perspective of building an operational system that works with ingest, and can work at scale!. We currently process ~200-300k files/day into the CEDA archive. These files are indexed using RabbitMQ to provide a stream of file paths and a modular indexer which can be scaled up on Kubernetes, or make use of our Lotus batch cluster, scaling to 100s of indexers if we need to do a big run. This forms the background to this work.
We are still experimenting and seeing what sticks at the moment, so things could change, but the general concept is that we will be dealing with a stream of data object identifiers. These could be traditional file paths on POSIX or object store URLs or even refer to data held on tape storage. All of these need to be processed to produce assets, items and collections.
We started thinking about top-down approaches that summarize the data in a location (tape, disk, object store). That looks nice from an optimisation perspective. For example, if you know a dataset is a time-series containing daily data from 1980-present. All files have the same structure and project metadata, only the time step changes. 15,000 files can be parameterised by reading the first and last, giving the time range and any other attributes of interest. However, this doesn’t work well with a stream of incoming data and requires custom code for each dataset to deal with the grouping rules.
So we switched the approach to bottom-up…
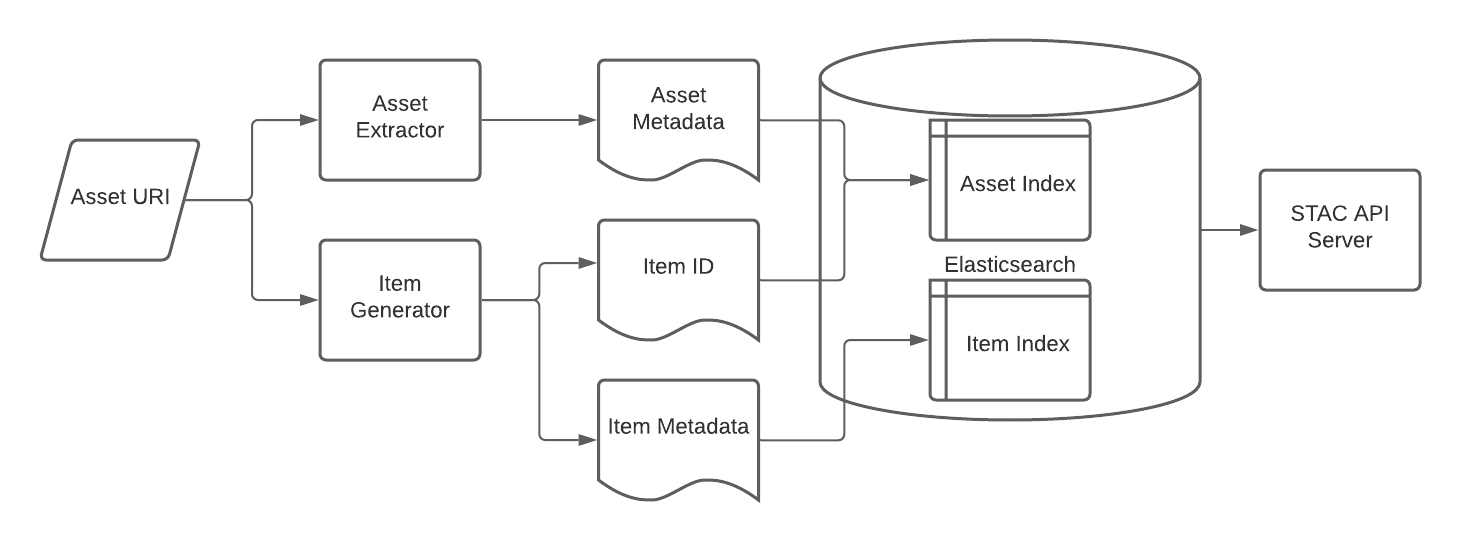
The asset-extractor aims to gather basic information about files and objects
which could be useful when presenting to the user (e.g. size, checksum, location) and/or data manager.
The item-generator aims to use the same file path/object URIs
(from now on called URIs) as the asset-extractor but tries to populate the properties field and other attributes of a
STAC item. The item-generator is currently focused on STAC items, but we haven’t yet thought about the mechanism for
generating collections. It is likely that this would remain top-down, as an aggregation of the items based on some
gathering rule (yet to be conceived). Both of these libraries are designed to work on atomic files and expect a file
path and will output a dictionary.
The asset-scanner provides the framework for these other two libraries to operate within,
allowing you to write a configuration file to define the inputs and outputs.
The input plugins provide a stream of URIs and the outputs decide what to do with the dictionary which comes out the other end.
In our use case, we have many different types, sources, formats and structures of data so we needed a way to define a bespoke processing chain for the different groups of common data.
Enter Item-descriptions.
These YAML files allow you to define a specific processing chain for URIs which match against it hierarchically.
DatasetNode('/', dataset=False)
└── DatasetNode('//badc', dataset=True, description_file='/descriptions/badc.yml')
├── DatasetNode('//badc/cmip5', dataset=False, description_file='descriptions/cmip5/cmip5.yml')
│ └── DatasetNode('//badc/cmip5/data', dataset=False, description_file='descriptions/cmip5/cmip5.yml')
│ └── DatasetNode('//badc/cmip5/data/cmip5', dataset=True, description_file='descriptions/cmip5/cmip5.yml')
└── DatasetNode('//badc/faam', dataset=False, description_file='descriptions/faam/faam.yml')
└── DatasetNode('//badc/faam/data', dataset=True, description_file='descriptions/faam/faam.yml')
An example of the tree built using the item-descriptions framework. The nodes
marked dataset=True are the locations described by the description file. This is the point the searching algorithm
matches against
As an example, given the URI:
/badc/cmip6/data/sftlf_fx_ACCESS-ESM1-5_esm-pi-CO2pulse_r1i1p1f1_gn.nc
processors defined in YAML file with following content would match.
datasets:
- /badc/cmip6
The item descriptions files live separately from the main configuration and are maintained as a separate repository. In an ideal world, data providers should be able to construct these description files when delivering the data as they are the ones most intimately familiar with the structure and will have insight on what attributes are most useful for their intended audience.
The framework is written to be extensible and allow for more processors to be added to generate/extract the required content from the files. The item-description also defines the facets which are important when constructing a STAC item. These facets should be present and extractable from all assets you wish to group together. These facets are then used to generate a unique ID for assets contacting those facets. The receiving application for the output from this process needs to handle the aggregation of responses with the same ID into STAC items.
It is perhaps also worth pointing out that although these tools are built around STAC Items and Assets, they are agnostic to the downstream application and could be used to build a flexible, scalable indexing operation to fuel other use cases.
As well as an indexing framework, we need a way to serve the data via the API. Here we have been extending and pushing improvments to the STAC FastAPI repository as well as building an elasticsearch backend. This is in early stages and effort will be taken to document at a later point. One point of concern is that both the upstream repo and our elasticsearch backend mix implementation and framework. This makes it harder for other people to use and customise and will need looking at in future.
Where next?
As a first pass, we are aiming for a minimum viable product. This means a processing chain to index the required metadata and a STAC API which can communicate with the data stored in Elasticsearch.
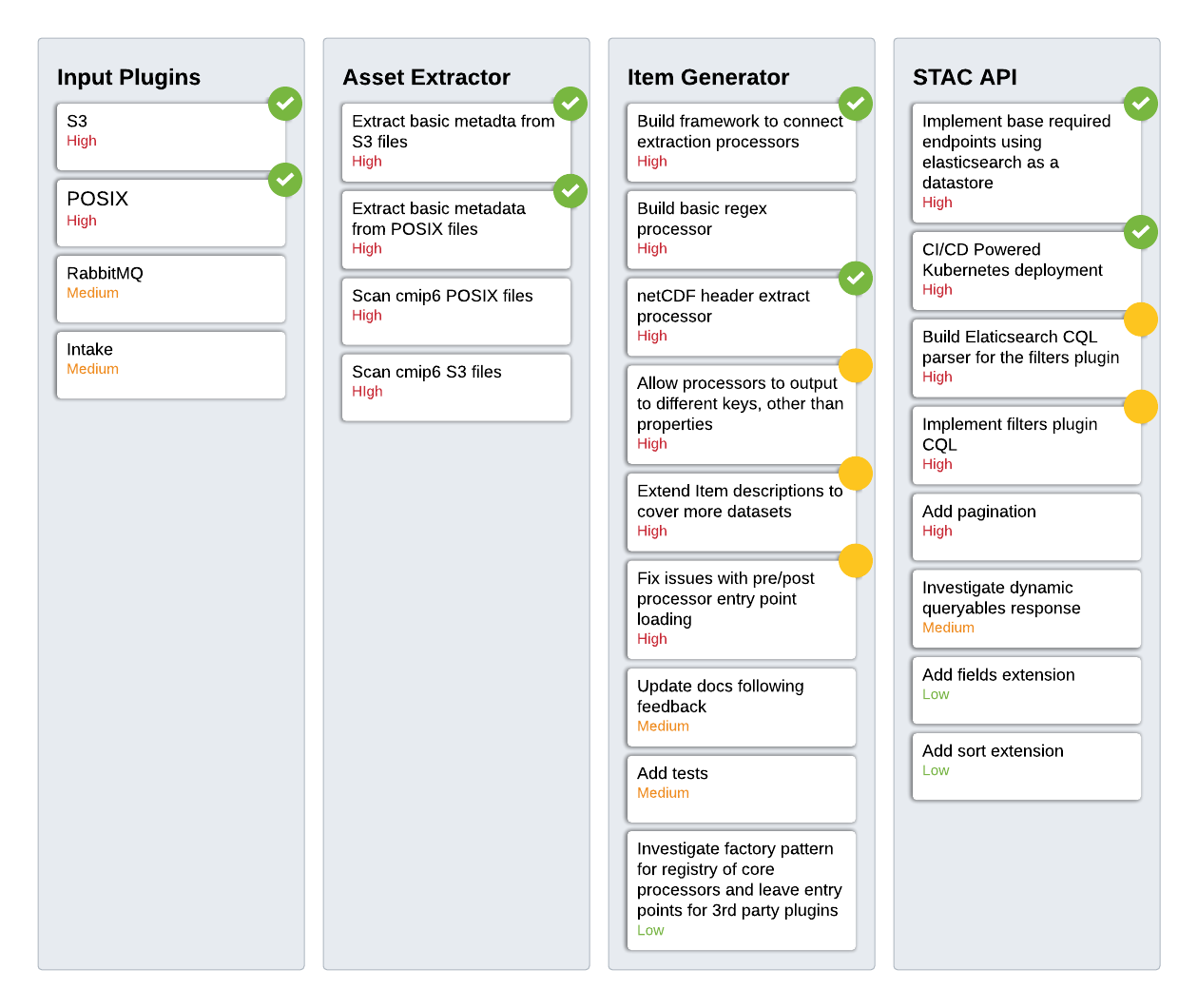
As we are building our implementation and tools, we are keeping an eye on and using (as much as possible) community tools as a base. The STAC specification is evolving fast and so are the tools around it. Extending the existing tools has necessarily required pushing improvements to upstream projects. Most of the changes have been to make progress in aligning more fully with the current specification or refactoring to aide in extending the code base.
One major piece of the puzzle, not discussed so far, is how to deal with the different vocabularies between domains and dataset collections. We would like to get to the point where each facet or properties attribute of an indexed STAC Item has been verified by a vocabulary server to find linked terms from other namespaces. The CCI Opensearch indexing process verifies the terms with a vocabulary server using triple stores to expand the terms extracted from the data files.
It would also be interesting to us to be able to use this approach on STAC server side as well, where user queries could be passed through the same process to enable cross domain searching.
Conclusion
We are hoping to solve our own challenges surrounding search and discovery of data and provide a framework which could be useful for other, similar archiving facilities. The combination of a nice developer-friendly JSON API and the collection of community tools and implementations at stacindex.org makes it likely that STAC will flourish. Working with the a range of environmental science communities in mind should help to broaden STAC’s usability. Opensearch provides a wholly flexible specification, which would work for us, but the lack of widespread community adoption limit the aspirations for wider uptake.
Software Stack
There are a lot of software repos being used and developed as part of this work as well as other software.
CEDA Repos
- stac-fastapi-elasticsearch - Elasticsearch backend for stac-fastapi
- pygeofilter-elasticsearch - Elaticsearch backend for OGC CQL parser
- asset-scanner - Indexing framework for indexing metadata
- asset-extractor - Indexing framework for gathering metadata about files
- item-generator - Indexing framework to generate STAC items
Community Repos
- stac-fastapi - FastAPI based server which provides a STAC API
- stac-pydantic - Data models and validation for STAC
- pygeofilter - OGC CQL (Common Query Language) parser