In July, we posted our progress so far and gave some intentions for the future. This post looks at the progress since then and showcases a minimum viable product looking at content generation, a web server and client tools.
This article assumes you have some background understanding of what we are doing. If you have not already, the background, requirements and progress sections of the previous blog will give the background.
We hope to create a full stack solution for other organisations with similar desires, including an indexing framework, API server, clients and vocabulary management. We have recently run a technical workshop looking at details of some of the following components. Recordings can be found here
Index
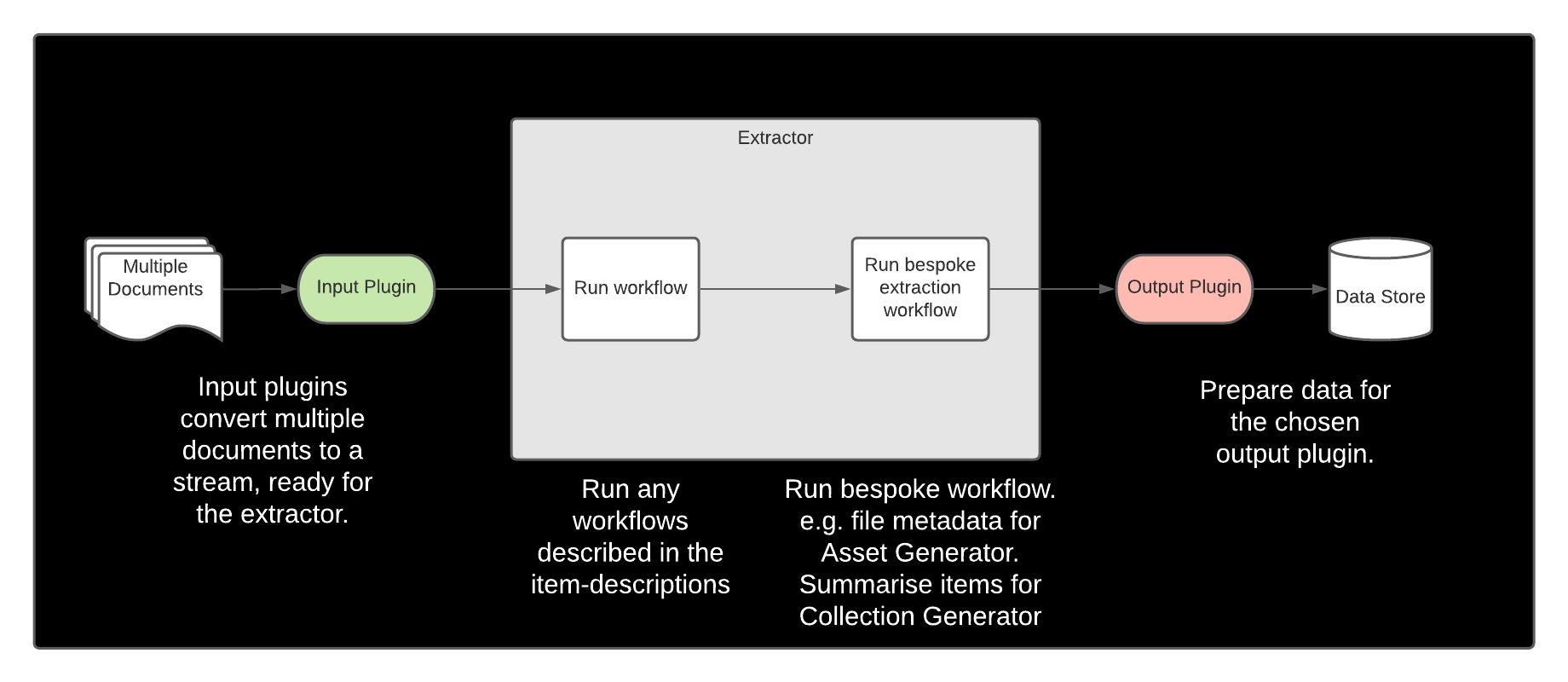
Indexing Framework
The first change is a bit of re-branding.
The indexing framework is lead by the asset-scanner.
This provides the base classes and includes the re-useable
processors, e.g. regex processor. The asset scanner also
provides the entry point to the indexing chain
via the command-line command asset_scanner.
Three more packages comprise the individual workflows to
convert a stream of assets into content for the STAC catalog.
They have been given the naming convention *-generator
Asset Generator
The asset generator is responsible for extracting basic file-level information needed for serving files.
- Location
- Size
- Last Modified
We have tested this system both against traditional disk filesystems and Object Store using Google Cloud and Amazon S3.
We are also in the process of adding support for property extraction at the asset level. For example, you might want to extract the datetime for a particular file. Although the STAC specification does not support searching these properties, it might be beneficial for downstream clients to have this information available.
Item Generator
The item generator forms the glue which brings together assets and collections. Collection IDs are pulled from the item description files and given to an item. Item IDs are generated, based on the content, and assigned to the relevant assets.
Item ID generation is what brings related assets together. The item generator pulls out named facets. Aggregation facets, defined in the item description, tell the system what constitutes a meaningful blob. All assets from which I can extract these facets, and their values are the same, are related.
This approach creates a different problem, discussed later.
Collection Generator
The collection generator works slightly differently to the other two. Whereas the asset and item generators are designed to work on a stream of assets, the collection generator works to summarise the related items.
It is conceivable that this could be run on a schedule, summarising daily or at whatever interval most fits your use case.
All 3 of the generators work on a similar pattern:
Remaining Challenges
It is certain that there are complexities which we have not addressed. Some that we are aware of and working to address:
- Item Aggregation
- Multiple access methods for a single asset
Item Aggregation
As we are using a stream of assets to create our items, the item metadata is generated as the granularity of assets.
So far, we have been allowing Elasticsearch to merge the JSON documents. This merge will add new keys and overwrite existing
keys. This has been fine but obvious errors occur with things like start_time/end_time for assets as part of a time series
and items for which multiple value for a given facet are valid.
Possible solutions:
- Push facet extraction to the asset level object and then aggregate assets to form items and items to form collections.
- Cache item objects and perform periodic merges of related objects before storing (could be queue or disk based)
STAC API
The second update comes to our API server. We are using STAC FastAPI a community project building a STAC server on the FastAPI framework. It comes with sample implementations for Postgres and using SQLAlchemy. We have developed an Elasticsearch backend.
Our current latest implementation is running at api.stac.ceda.ac.uk.
Aside from porting the base API to work with Elasticsearch, we have created an Elasticsearch
backend for pygeofilter
to enable us to provide the filter extension. This gives
rich search capability. It also provides queryables which describe the facets available for
each collection. Through this mechanism, there is no finer reduction of facets.
One of our desires was free-text search capability. This is not defined in the specification.
Technically, you could probably construct queries using the filter extension which would
satisfy this need but users are familiar with simple querystring syntax. Elasticsearch
provides powerful free-text capabilities, so we have added an extension providing simple
search using the q parameter.

This extension has been listed on the official stac-api-specification page and is available for all to use.
Faceted search is high on our priority list and we have been trying out solutions.
The /collections/<id>/queryables endpoint gives collection level facets. The
global /queryables endpoint gives the intersection of all available facets. There is
difficulty in providing these values for a heterogeneous archive as intersecting more than 2
collections with different facets will tend to zero.
To solve this, we have defined the context collections extension.
This returns the top
10 (elasticsearch default) collections for the current search. This can then be supplied
to the /queryables endpoint using /queryables?collections=col1,col2 as suggested in
issue-156. This works but
you cannot reduce your facet availability below the collection level as the queryables endpoints
/queryables /collections/<id>/queryables have no concept of search. To avoid making the search
twice, we will try returning the facets in the context in a similar approach to Google.
This issue is tracked in issue-182.
STAC Clients
Although the API is very powerful we will want a user interface to package the API.
Web UI
The simplest user interface (UI) is a web browser allowing us to visually represent the datasets and interact through a point-and-click interface.
Community options are 2-fold:
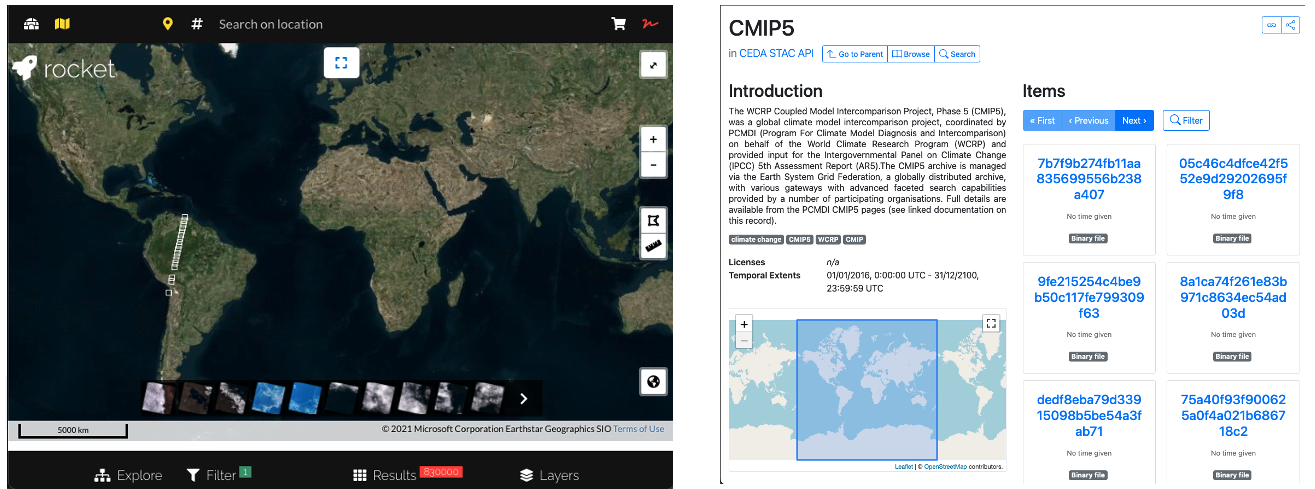
Rocket provides a great map-centric interface. As much of our data compises global datasets, this is less relevant. The STAC browser works with our implementation of STAC but with reduced functionality. We wanted to be able to move quickly and try new features (free-text search, faceted search) and so have developed our own ReactJS web client.
It is loosely based on STAC browser and is mostly un-styled to allow it to be used and customised by other institutions.
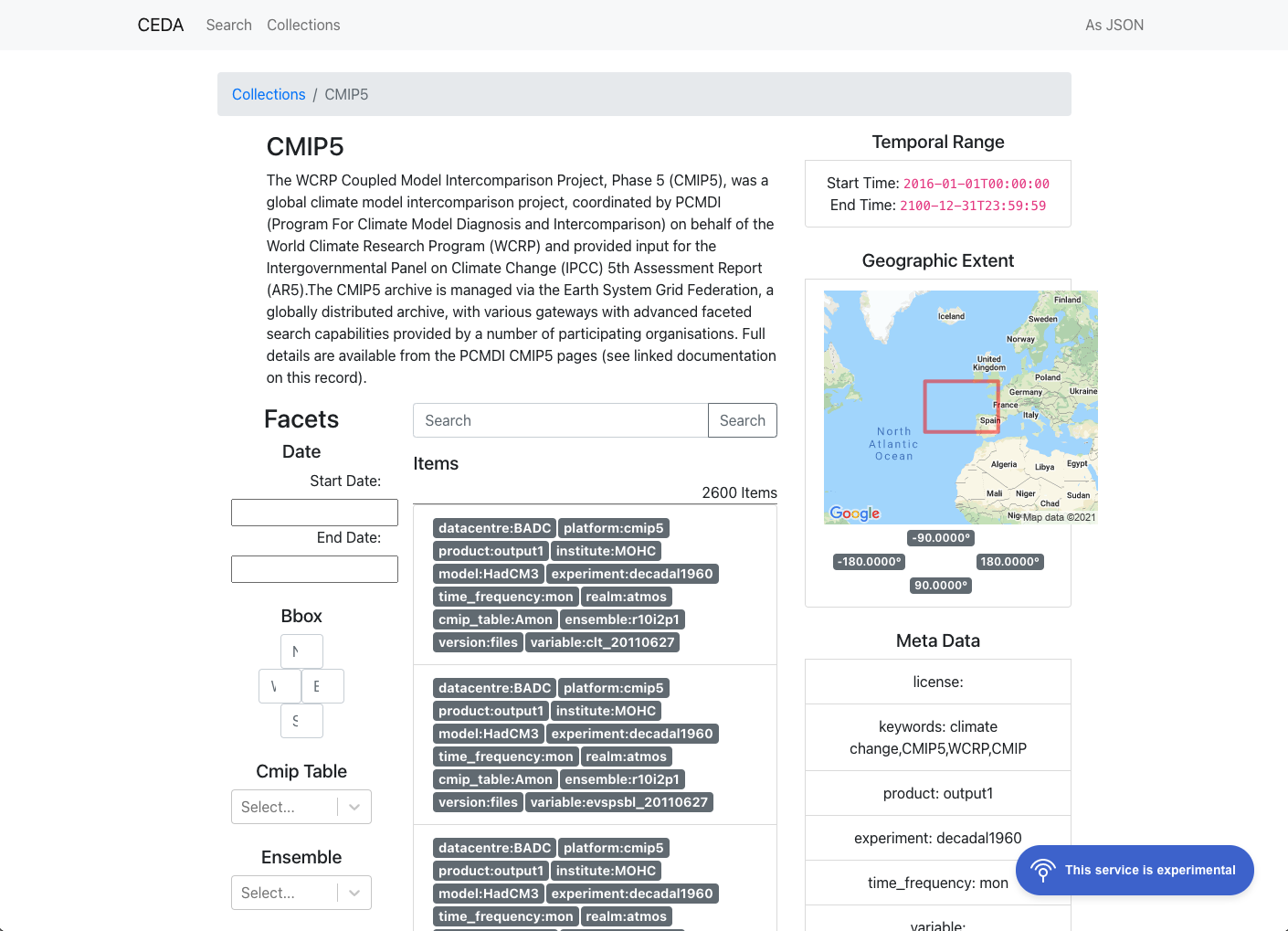
We have a running, experimental example at stac.ceda.ac.uk.
Python Client
For programmatic interactions, it is helpful to wrap the REST API in objects with convenience functions and hide some complexity forming the requests.
There are more options from the community in this area. We have developed an early example based on stac.py.
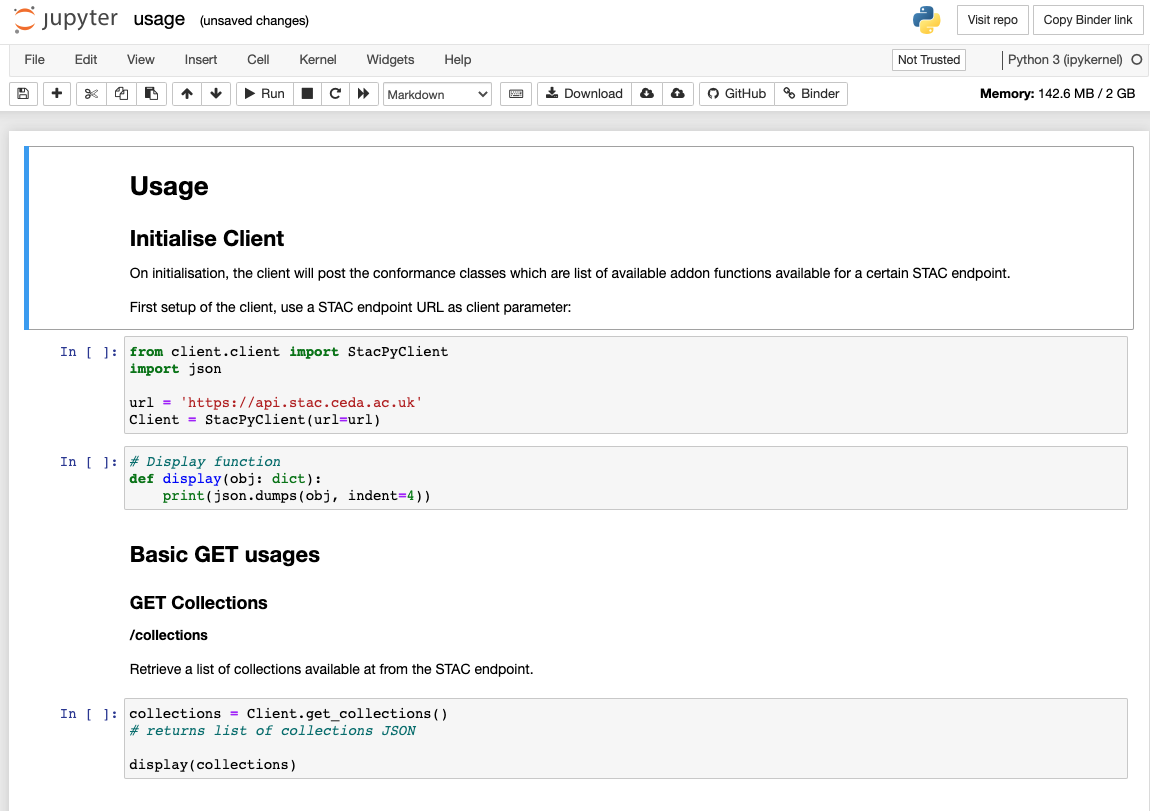
This client can perform faceted search. Sadly it seems that stac.py is going out of development. We will review the alternative options in the new year.
Vocabulary Management
With diverse data there is the desire to manage vocabularies and deliver a rich experience
to the user. As a first pass, we want to map project specific terms to more general terms.
For example cmip6:source_id --> model. Then we want to bring contextual data to the user through
the clients (e.g. Hovering over a term in the web UI will open a box explaining the term and provide links
to other resources where you can read about it).
The key points with this are:
- We are not going to be too scientific about it. As long as a term has a close enough relationship that a non-technical user wouldn’t see a difference, it is a good match regardless of any nuance.
- This is not a vocab server. We are not trying to replace other vocabulary servers, only collate information from disparate sources to enhance the search experience.
- We are not doing strict vocab checking during indexing. We will not be using this service to restrict what can become a facet. This allows the indexing process to remain flexible and not be delayed by needing to update the official vocabularies.